「うちの業務は特に問題なく回っている」「どこを改善すればいいかは、現場が一番わかっている」――こうした声は、業務改善やAIエージェント導入の検討を始めた企業でよく聞かれます。
しかし、実際にシステムのデータを分析してみると、現場の誰も気づいていなかったムダが次々と見つかるケースが少なくありません。承認プロセスでの不要な差し戻し、特定の担当者への業務集中、部門間の受け渡しでの長時間の滞留……。こうした「見えないムダ」は、ヒアリングやアンケートだけでは表に出てきません。
本記事では、プロセスマイニングがなぜ従来の業務分析手法では見えなかった課題を発見できるのか、その仕組みから、AIエージェントの導入ポイント特定、そして導入計画へのつなげ方までを解説します。
なぜ業務のムダは現場のヒアリングだけでは見えないのか
担当者は「自分の当たり前」を問題だと認識できない
業務改善のプロジェクトでは、まず現場担当者へのヒアリングから始めるのが一般的です。しかし、この方法には根本的な限界があります。担当者が語るのは「自分が認識している業務の流れ」であり、毎日繰り返す手順にムダがあるとは気づきにくいのです。
たとえば、「承認依頼のメールが来たら、まずExcelの管理台帳に転記してから処理する」という手順を10年続けてきた担当者は、その転記作業がボトルネックになっているとは思いません。同様に、属人化が進んだ業務では、本人も周囲もその状態を「仕方がないこと」として受け入れています。
ヒアリングで得られるのは「理想化されたプロセス」
もうひとつの問題は、ヒアリングで得られる情報が実態よりも整理された「理想の姿」になりがちなことです。実際には差し戻しが何度も発生していたり、急ぎの案件だけ別ルートで処理されていたりしますが、こうした例外や逸脱は本人の記憶から抜け落ちやすいのです。
ヒアリングで作成したフロー図と実際のシステムログから再現したフロー図を比較すると、想定外の処理パターンが全体の30〜50%を占めていたケースも報告されています。ヒアリングだけでは業務の半分近くを見落としている可能性があるのです。
「全社的な業務の健康診断」ができない
ヒアリングベースの分析にはスケーラビリティの問題もあります。全社横断で数十の業務プロセスを同時に分析することは現実的ではありません。プロセスマイニングは、業務システムのイベントログを分析することで、人の記憶に頼らず、事実に基づいた業務の全体像を描き出します。
【ガバナンス視点】個人の監視ではなく「プロセスの改善」へ
プロセスマイニングはシステムログという「事実」に基づき業務を可視化しますが、これは「従業員の働きぶりを監視する」ためのものではありません。分析の実施にあたっては、個人名や社員番号をハッシュ化(匿名化)して取り込むなど、プライバシーに配慮したデータマスキング運用が可能です。目的はあくまで、特定の担当者に負荷が集中する「仕組みの欠陥」を見つけ出し、AIエージェントでその負担を軽減することにあります。
イベントログから実際の業務フローを再現する仕組み
プロセスマイニングは、業務システムが日々記録している「イベントログ」を活用します。必要なデータは基本的に次の3つだけです。
ケースIDは個々の案件を識別する番号(注文番号、申請番号など)、アクティビティは実行された処理の名前(「申請」「承認」「差し戻し」など)、タイムスタンプは処理が実行された日時です。
この3要素をツールに取り込むと、業務フローが自動的に再現されます。再現されるフロー図は「理想の流れ」ではなく、実際に起きたすべてのパターンを反映したものです。差し戻しのループ、スキップされたステップ、例外的な処理ルートもすべてデータに基づいて描き出されます。
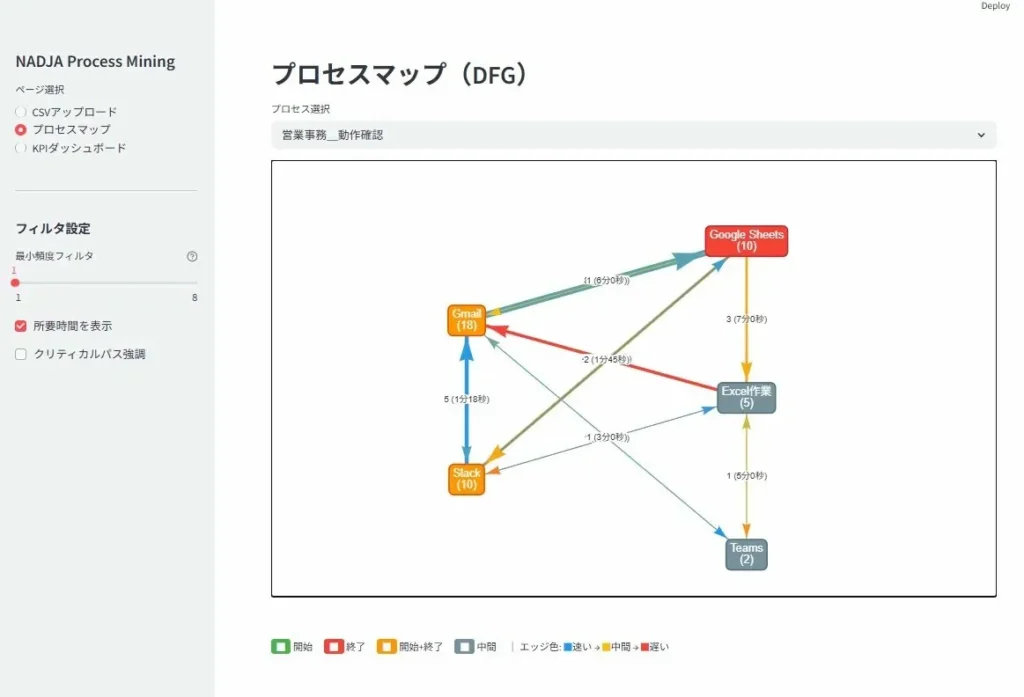
多くの企業がすでに使っている業務システム(SAP、Salesforce、kintoneなど)には分析に必要なイベントログが蓄積されており、新たなシステムを導入しなくても分析を開始できます。
可視化によって発見されるボトルネックと非効率の典型パターン
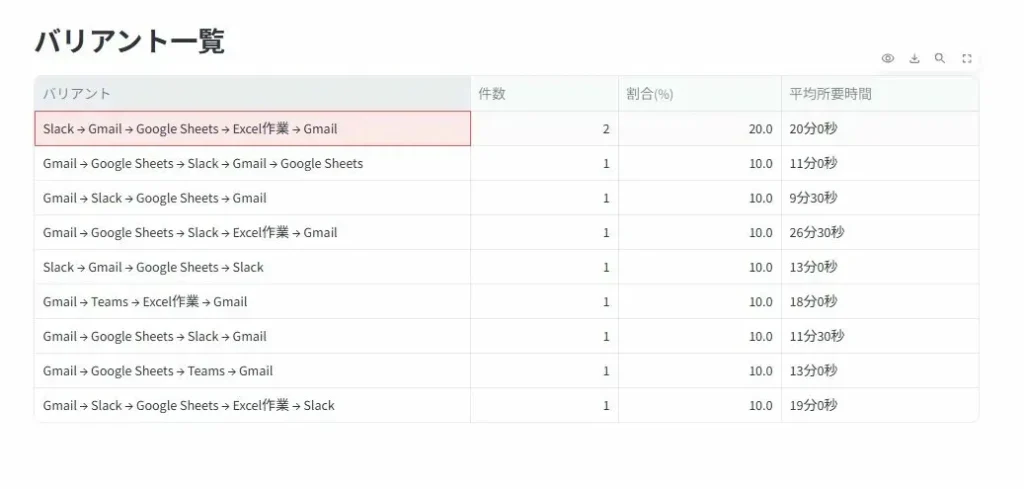
プロセスマイニングで業務を可視化すると、以下のような典型的な問題パターンが浮かび上がります。
- パターン1:繰り返される差し戻しのループ
「記入漏れ→差し戻し→再申請→別の不備で再度差し戻し」といったループの累積コストの大きさが、データから見えてきます。現場では個別の事象として処理しているため、全体でどれほどの時間ロスが生じているかを認識できていません。 - パターン2:特定の担当者への業務集中(属人化)
特定の人に処理が集中している偏りが数字で現れます。これは業務効率だけでなく、リスク管理の観点からも重要な課題です。 - パターン3:部門間の受け渡しでの滞留
部署をまたぐ際に案件が放置される時間を、正確な数値(例:平均4.2日のアイドルタイム)で特定できます。 - パターン4:想定外の例外ルートの多発
過去の応急処置が定着し、マニュアルにない例外処理が全体の大きな割合を占めている実態が明らかになります。標準フローでは3ステップで完了するはずが、実際には平均7.5ステップかかっている、というケースもあります。
「どこにAIエージェントを入れるべきか」をデータから判断する
AIエージェントは万能ではないからこそ、「感覚」ではなく「データ」で導入先を決めることが重要です。判断の軸は以下の4つです。
①定型率――ハッピーパスが全体に占める割合。70%以上なら有力候補です。
②ボリューム――月間処理件数。定型率との掛け合わせで削減できる総工数を見積もります。
③滞留時間――人が介在する承認待ちや手動振り分けに時間がかかっている箇所を特定します。
④エラー・差し戻し率――AIによる事前チェックで改善効果が見込めるステップを洗い出します。
これらを組み合わせると、たとえば次のような施策が導き出せます。
- 差し戻しが多いステップには、AIによる申請内容の事前チェックを入れる。
- 滞留が長い受け渡しポイントには、AIによる自動振り分けや優先度判定を導入する。
- 定型的な問い合わせ対応には、AIエージェントによる一次対応の自動化を適用する。
優先順位づけの詳しいフレームワークについては、子ページ②で解説しています。
可視化から導入計画へつなげるステップ
- ステップ1:対象業務の選定とデータ取得
「受発注業務」「経費精算」など特定の領域に絞ってスモールスタートし、必要なイベントログを取得します。 - ステップ2:現状の可視化と課題の特定
プロセスマイニングで業務フローを可視化し、ボトルネック・差し戻し・滞留・例外ルートを洗い出します。現場へのヒアリングも併用し、データと感覚のギャップを確認します。 - ステップ3:AIエージェント導入ポイントの優先順位づけ
4つの判断軸で評価し、「効果が大きい × 実現しやすい」業務から着手する計画を立てます。 - ステップ4:導入前のベースライン計測
処理時間、エラー率、差し戻し率などを「ベースライン」として記録し、導入後の効果測定(→子ページ③)に備えます。 - ステップ5:導入とモニタリング
AIエージェント導入後、プロセスマイニングで継続的にモニタリングし、改善効果を数値で把握します。期待した効果が出ていない場合も、データから原因を特定し迅速に改善できます。
まとめ
プロセスマイニングは、ヒアリングだけでは見えない業務のムダをデータで可視化し、AIエージェントの最適な導入ポイントを根拠を持って特定する手法です。
NADJAでは、自社開発ツールによる業務の可視化からAIエージェントの設計・導入、効果測定、そしてプライバシーに配慮したガバナンスルールの策定までを一貫して支援しています。「どこから手をつければいいかわからない」という方は、まずお気軽にご相談ください。
※本記事は、プロセスマイニングとは?AIエージェント導入の成果を最大化する業務分析手法の全体像の子ページ①です。
▶ 関連記事:AIエージェント導入前の業務分析|プロセスマイニングで自動化すべきプロセスを正しく見極める(子ページ②)
▶ 関連記事:AIエージェント導入後の効果計測|プロセスマイニングで改善インパクトを数値で証明する(子ページ③)
▶ 関連記事:DX推進を加速させるプロセスマイニング×AIエージェントの相乗効果(子ページ④)